


Chasing Causal Holy Grails: Quantifying Advertising Success
Have you ever wondered how valuable your marketing campaigns really are? Typically, companies use machine learning capabilities to target “ideal” prospects and may create profiles of audiences based off their data. These efforts, however, are fundamentally centered on the premise that a predictive model is equivalent to a descriptive or causal model, which is far from the truth. In this blog, we’ll explore the differences between the two, as well as the value of causal models and how we’re using them at Zeta.
In advertising, there are two “holy grails” for machine learning:
1. The ability to deduce the “true” effect of variables, such as location and certain search keywords, on the propensity to purchase your product.
Knowing this provides insight and value not only for the immediate campaign but also for your client’s marketing strategy.
2. Optimization of your campaign’s targeting ability to the people that are most affected by it (incrementality).
We don’t want to waste money by targeting people that are already going to purchase an item. Instead, we want to be defined by our ability to actively change behaviors purely by our advertising efforts.
While existing predictive models can achieve the above to a limited degree, there are serious underlying issues in their abilities. We’ll discuss these limitations below, and demonstrate how causal models can generate strategic insights, decrease wasteful spending, and increase the impact of your campaign on changing outcomes (henceforth referred to as incrementality).
So why is this important? If your method of describing a variable’s effect on outcome Y is through a predictive model such as logistic regression, then your method may be flawed.
In predictive modeling, all that you care about is how well your algorithm can predict a given outcome. Therefore, you are willing to accept conditions that violate key assumptions in your model such as endogeneity and ignore issues such as multicollinearity, as long as the overall predictive power is high.
To counter these problems, we need to carefully assess the sources of endogeneity and identify issues that may contaminate our interpretations and beliefs surrounding our models be it from the predictors (predictor is another term for variable), data generation process, or otherwise. Zeta’s curation of relevant predictors and modeling processes are constructed on precisely this premise to deliver value to our customers.
Given these problems, why are simple predictive models so successful? Well, strictly speaking for predictive models, it doesn’t matter if your estimate of an individual variable’s effect on outcome Y is accurate, as long as the model in its entirety is able to predict the right outcome.
For example, with highly correlated predictors “A” and “B,” it’s perfectly possible that our model’s estimate for “A” is below the true value of “A,” as long as the model compensates for this by making the estimate for “B” higher than its true value. The total effect of “A” and “B” are the same, but the individual estimates for “A” and “B” are now off.
We are unable to necessarily interpret individual effects of the variables in our models as causal if our model is predictive in nature.
We here at Zeta actively combat against issues such as these to ensure our models are both reliably interpretable for our clients while maintaining high predictive power through the use of model constraining techniques, external validation, and a series of statistical tests and procedures.
For most advertisers, machine-learning algorithms are built to optimize on people who are most likely to convert (purchase an item). However, we’re asking the wrong question here. What we’re interested in isn’t who is likely to purchase an item, it’s whose behavior is most likely to change due to our ads.
This is a crucial difference! In the former case, we are sending ads to people who would have purchased an item anyways, with or without having seen your ad. Sure, the campaign might show a high number of conversions (people that have purchased after seeing your ad), but how much impact has the campaign actually had? In the latter, we avoid this wasteful spending and optimize purely on the impact we can have.
To understand this, we use incrementality testing, which splits our total prospects into two groups: treatment and control. We ensure both groups are homogenous in how likely they are to purchase an item. The only difference between the groups is that the treatment group receives an ad while the control group does not. Once the campaign is finished, we’ll compare the average probability of someone converting in the treatment group against someone in the control group. In statistics, we call this the Average Treatment Effect (ATE).
At Zeta, we asked if we could go one step further. Can we estimate the “true” or causal impact of our ads, at an individual level? If so, we can optimize our ads on an individual level to maximize our impact.
To answer both questions (the true effect of our predictors on an outcome and optimizing on incrementality), we need to understand how to convert predictive models into causal ones. To do so, we need to understand how the assumptions of our models were violated for predictive modeling and adjust our models accordingly.
Typically, models suffer from a variety of assumption violations, but most notable amongst these are selection bias and omitted variable bias. For brevity’s sake, we won’t discuss these in detail. But usually selection bias and omitted variable bias require thoughtful consideration of what predictors we put in our model. We also need to consider other forms of endogeneity, which is when our model’s predictors are correlated with the error term. The error term is the model’s way of understanding that variation in an outcome between data points of the same value is natural and ideally random. For example, if our model considers location and browser history, it is fine for people who have the same location and similar browser history to have variation in their decisions.
To deal with more complex forms of endogeneity, we have a variety of tools at our disposal, which stem from fields as varied as econometrics to epidemiology. Chief among these are instrumental variables, regression discontinuity, and Bayesian Networks.
At Zeta, we’ve found that while those methods succeed at isolating the “true effect” of variables by removing biases from our variables of interest, they often lack predictive power. This does, however, provide valuable strategic insight into predictors, accomplishing the first question.
To deal with the second question, we’ve borrowed some insights from the medical field. Within the medical field, practitioners face a serious problem of heterogeneous treatment effects. In other words, certain sub-groups in a population will respond to the same medical treatment differently. We thus transform the problem of estimating individual incrementality to a related but more tractable problem: can we identify sub-groups in our campaigns that have abnormally high response rates? If we can identify these sub-groups as well as remove sub-groups with lower-than-average response rates, we can use a series of other statistical modeling techniques to optimize specifically for these groups and increase our overall incrementality.
Contact us today!
The holy grails of advertising
In advertising, there are two “holy grails” for machine learning:
1. The ability to deduce the “true” effect of variables, such as location and certain search keywords, on the propensity to purchase your product.
Knowing this provides insight and value not only for the immediate campaign but also for your client’s marketing strategy.
2. Optimization of your campaign’s targeting ability to the people that are most affected by it (incrementality).
We don’t want to waste money by targeting people that are already going to purchase an item. Instead, we want to be defined by our ability to actively change behaviors purely by our advertising efforts.
While existing predictive models can achieve the above to a limited degree, there are serious underlying issues in their abilities. We’ll discuss these limitations below, and demonstrate how causal models can generate strategic insights, decrease wasteful spending, and increase the impact of your campaign on changing outcomes (henceforth referred to as incrementality).
Differences between predictive and causal models
So why is this important? If your method of describing a variable’s effect on outcome Y is through a predictive model such as logistic regression, then your method may be flawed.
In predictive modeling, all that you care about is how well your algorithm can predict a given outcome. Therefore, you are willing to accept conditions that violate key assumptions in your model such as endogeneity and ignore issues such as multicollinearity, as long as the overall predictive power is high.
To counter these problems, we need to carefully assess the sources of endogeneity and identify issues that may contaminate our interpretations and beliefs surrounding our models be it from the predictors (predictor is another term for variable), data generation process, or otherwise. Zeta’s curation of relevant predictors and modeling processes are constructed on precisely this premise to deliver value to our customers.
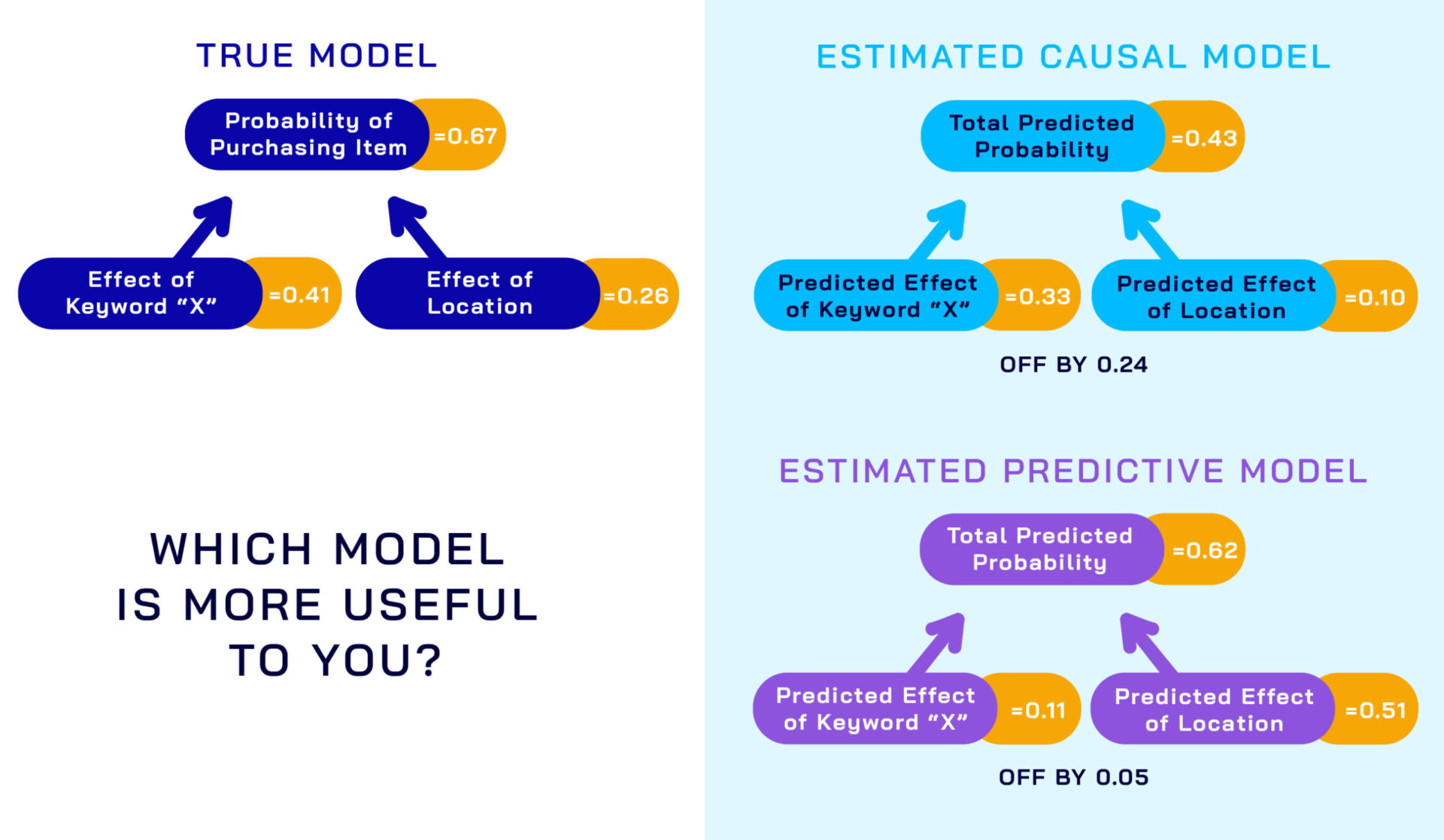
Given these problems, why are simple predictive models so successful? Well, strictly speaking for predictive models, it doesn’t matter if your estimate of an individual variable’s effect on outcome Y is accurate, as long as the model in its entirety is able to predict the right outcome.
For example, with highly correlated predictors “A” and “B,” it’s perfectly possible that our model’s estimate for “A” is below the true value of “A,” as long as the model compensates for this by making the estimate for “B” higher than its true value. The total effect of “A” and “B” are the same, but the individual estimates for “A” and “B” are now off.
We are unable to necessarily interpret individual effects of the variables in our models as causal if our model is predictive in nature.
We here at Zeta actively combat against issues such as these to ensure our models are both reliably interpretable for our clients while maintaining high predictive power through the use of model constraining techniques, external validation, and a series of statistical tests and procedures.
Estimating the impact of our campaigns
For most advertisers, machine-learning algorithms are built to optimize on people who are most likely to convert (purchase an item). However, we’re asking the wrong question here. What we’re interested in isn’t who is likely to purchase an item, it’s whose behavior is most likely to change due to our ads.

This is a crucial difference! In the former case, we are sending ads to people who would have purchased an item anyways, with or without having seen your ad. Sure, the campaign might show a high number of conversions (people that have purchased after seeing your ad), but how much impact has the campaign actually had? In the latter, we avoid this wasteful spending and optimize purely on the impact we can have.
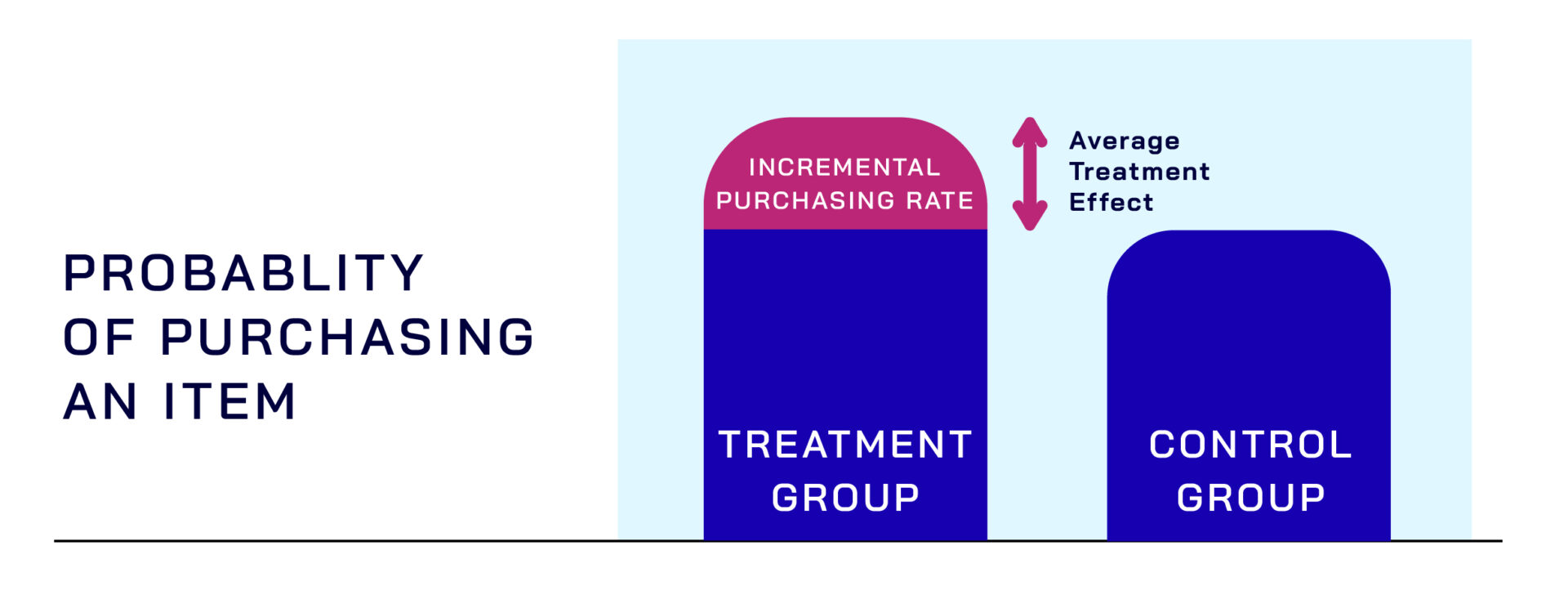
To understand this, we use incrementality testing, which splits our total prospects into two groups: treatment and control. We ensure both groups are homogenous in how likely they are to purchase an item. The only difference between the groups is that the treatment group receives an ad while the control group does not. Once the campaign is finished, we’ll compare the average probability of someone converting in the treatment group against someone in the control group. In statistics, we call this the Average Treatment Effect (ATE).
At Zeta, we asked if we could go one step further. Can we estimate the “true” or causal impact of our ads, at an individual level? If so, we can optimize our ads on an individual level to maximize our impact.
Causal modeling at Zeta
To answer both questions (the true effect of our predictors on an outcome and optimizing on incrementality), we need to understand how to convert predictive models into causal ones. To do so, we need to understand how the assumptions of our models were violated for predictive modeling and adjust our models accordingly.
Typically, models suffer from a variety of assumption violations, but most notable amongst these are selection bias and omitted variable bias. For brevity’s sake, we won’t discuss these in detail. But usually selection bias and omitted variable bias require thoughtful consideration of what predictors we put in our model. We also need to consider other forms of endogeneity, which is when our model’s predictors are correlated with the error term. The error term is the model’s way of understanding that variation in an outcome between data points of the same value is natural and ideally random. For example, if our model considers location and browser history, it is fine for people who have the same location and similar browser history to have variation in their decisions.
To deal with more complex forms of endogeneity, we have a variety of tools at our disposal, which stem from fields as varied as econometrics to epidemiology. Chief among these are instrumental variables, regression discontinuity, and Bayesian Networks.
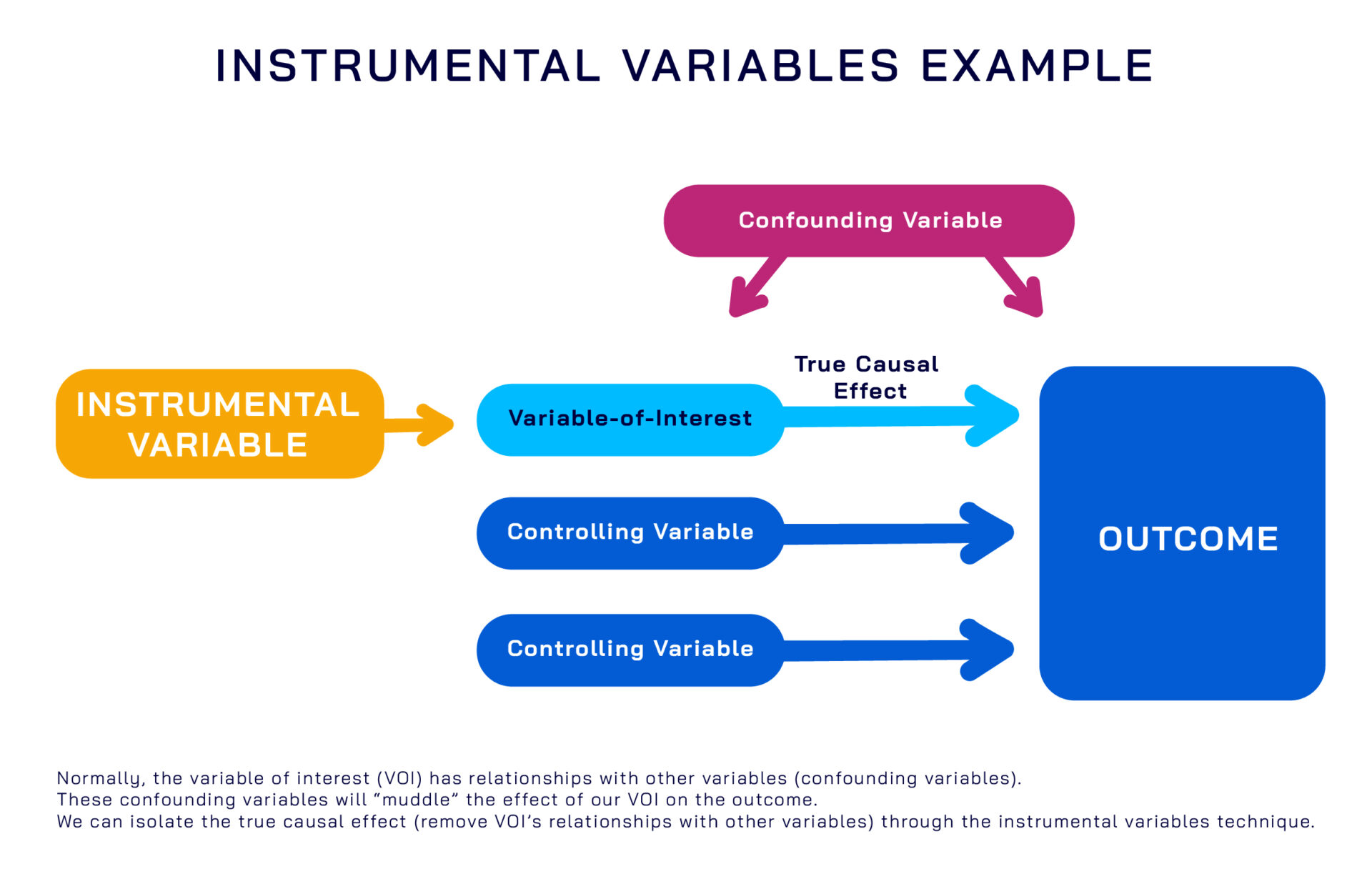
At Zeta, we’ve found that while those methods succeed at isolating the “true effect” of variables by removing biases from our variables of interest, they often lack predictive power. This does, however, provide valuable strategic insight into predictors, accomplishing the first question.
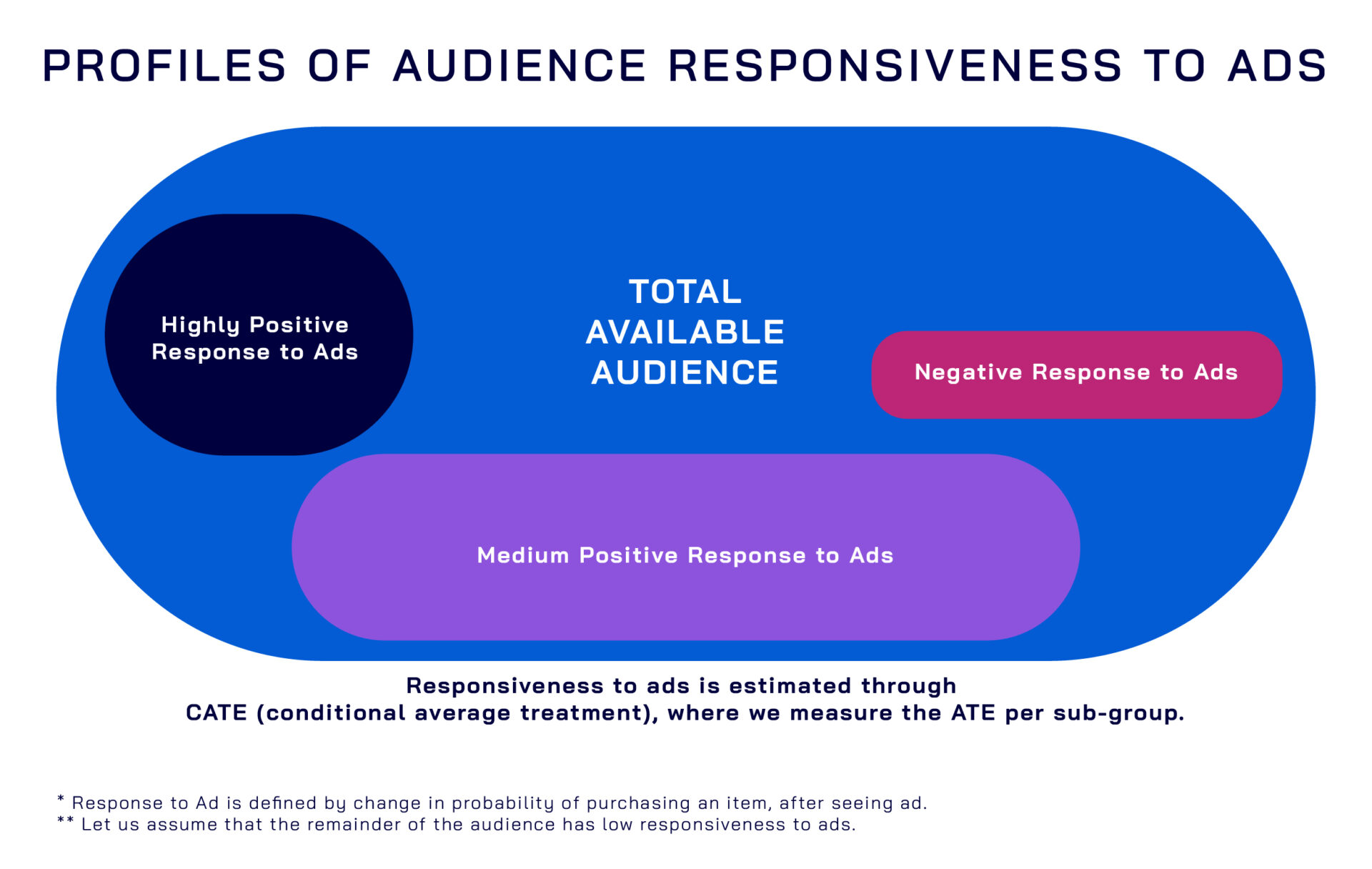
To deal with the second question, we’ve borrowed some insights from the medical field. Within the medical field, practitioners face a serious problem of heterogeneous treatment effects. In other words, certain sub-groups in a population will respond to the same medical treatment differently. We thus transform the problem of estimating individual incrementality to a related but more tractable problem: can we identify sub-groups in our campaigns that have abnormally high response rates? If we can identify these sub-groups as well as remove sub-groups with lower-than-average response rates, we can use a series of other statistical modeling techniques to optimize specifically for these groups and increase our overall incrementality.
Want to further discuss how causal inference and incrementality may help your campaigns?
Contact us today!






